Multi-View Foundation Models
Coming soon
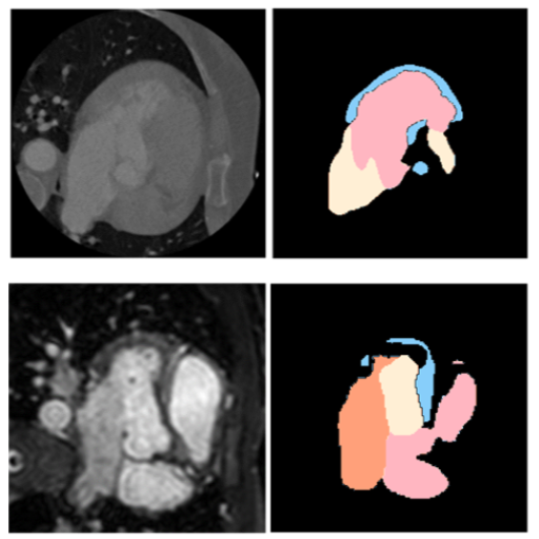
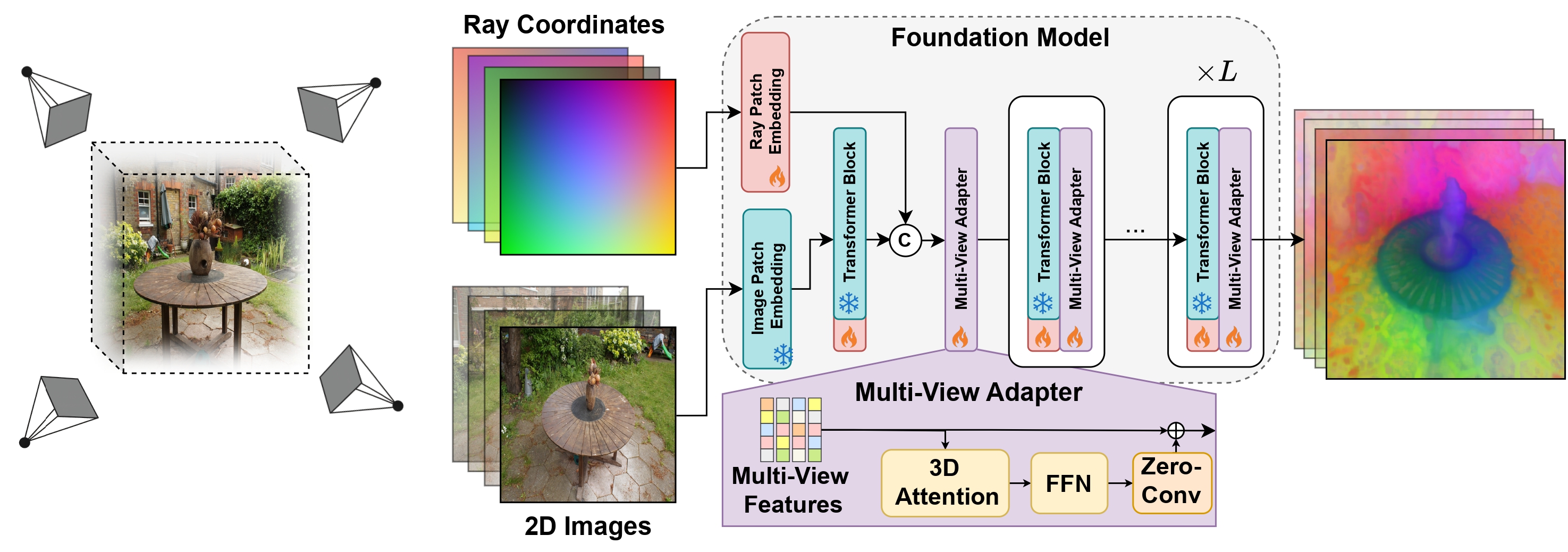
We introduce multi-view foundation models that equip powerful 2D vision backbones with the ability to reason jointly across multiple camera views. By explicitly incorporating camera geometry, our approach produces 3D-consistent semantic representations without per-scene optimization, enabling scalable 3D understanding and correspondence.